In the language introduced yesterday, mutable parameters play the important role of representing the side effects of actions in the type system and thus ensure referential transparency.
One of the questions currently unaddressed is how to handle currying in the presence of mutable parameters. In order to visualise this problem, consider a function
printLn(mutable IO, String line)
If we bind the the first parameter, what should be the type of the function, and especially important how do we get back the mutable parameter? Consider the partially applied form printLn1:
printLn1(String line)
The mutability parameter would be lost and we could not do any further I/O (and the curried form would appear as a pure function, so a good compiler would not even emit a call to it) An answer might be to put the thing into the result when currying:
printLn2(String line) -> mutable IO
But how can we explain this? In the end result, do we maybe have to use a signature like:
printLn(String, mutable in IO io1, mutable out IO io2)
We could then introduce syntax to call that as
printLn(string, mutable io)
Where as the mutable io argument basically expands to io and io1 for the first call, and for later calls to io1, io2 , and so on. It can also be easily curried by allowing currying to take place on variables not declared as output parameters. We can then curry the function as:
printLn3(mutable in IO io1, mutable out IO io2)
printLn4(mutable out IO io2)
If so, we can rename mutable back to unique and make that easier by introducing the unary operator
& for two locations, just like Mercury uses
! for it. We could then write calls looking like this:
printLn("Hello", &io);
printLn("Hello", io, io1);
How out parameters are explained is a different topic; we could probably say that an out parameter defines a new variable.
Another option is to forbid currying of mutable parameters entirely. This would have the advantage of maintaining the somewhat simple one parameter style.
The programming language
Clean does not provide any special syntactic sugar for having mutable variables. In Clean, the function gets a unique object and returns a unique object (noted by
*). For example, the main entry point in a Clean program (with state) looks like this:
Start:: *World -> *World
In short, the function Start gets a abstract world passed that is unique and at the end returns a new unique world. In Clean syntax, our example function would most likely have the signature:
printLn :: String *IO -> *IO
You know have to either maintain one additional variable for the new unique object, which gets a bit complicated with time. On the other hand, you can do function composition on this (if you have a function composition operator that preserves uniqueness when available, as should be possible in Clean):
printTwoLines :: *IO -> *IO
printTwoLines = (printLn "World") o (printLn "Hello")
Function composition on mutable things however, does not seem like it is needed often enough in a functional programming language with a C syntax.
People might also ask why monads are not used instead. Simon L Peyton Jones and Philip Wadler described monadic I/O in their paper Imperative Functional Programming (
http://research.microsoft.com/en-us/um/people/simonpj/papers/imperative.ps.Z) in 1993, and it is used in Haskell (the paper was about the implementation in Haskell anyway), one of the world s most popular and successful functional programming languages.
While monadic I/O works for the Haskell crowd, and surely some other people, the use of Monads also limits the expressiveness of code, at least as far as I can tell. At least as soon as you want to combine multiple monads, you will have to start lifting stuff from one monad to another (
liftIO and friends), or perform all operations in the IO monad, which prevents obvious optimizations (such as parallelizing the creation of two arrays) in short dependencies between actions are more strict than they have to be. For a functional language targeting imperative programmers, the lifting part seems a bit too complicated.
One of the big advantages of monads is that they are much easier to implement, as they do not require extensions to the type system and the Hindley-Milner type inference algorithm used by the cool functional programming languages. If you want uniqueness typing however, you need to modify the algorithm or infer the basic types first and then infer uniqueness in a second pass (as Clean seems to do it).
Filed under:
General 









 On Wednesday, I successfully defended my PhD dissertation in front of a ridiculously packed house at the MIT Media Lab. I am humbled by the support shown by the MIT Sloan, Media Lab, and Harvard communities. Earlier today, I finished up paperwork and submitted my archival copies. I m done.
Although I ve often heard
On Wednesday, I successfully defended my PhD dissertation in front of a ridiculously packed house at the MIT Media Lab. I am humbled by the support shown by the MIT Sloan, Media Lab, and Harvard communities. Earlier today, I finished up paperwork and submitted my archival copies. I m done.
Although I ve often heard 


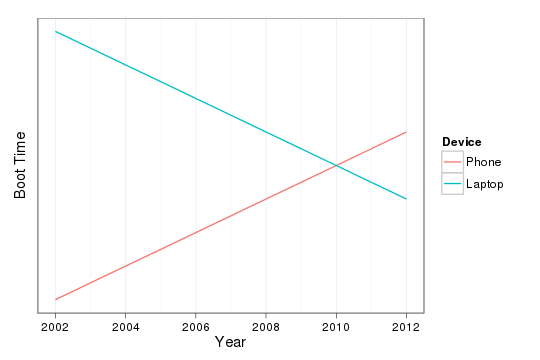 As the graph indicates, I think my cross-over was around 2010 when
I acquired an
As the graph indicates, I think my cross-over was around 2010 when
I acquired an 






 here's the list of RC bugs I've worked on during the last week:
here's the list of RC bugs I've worked on during the last week:



















































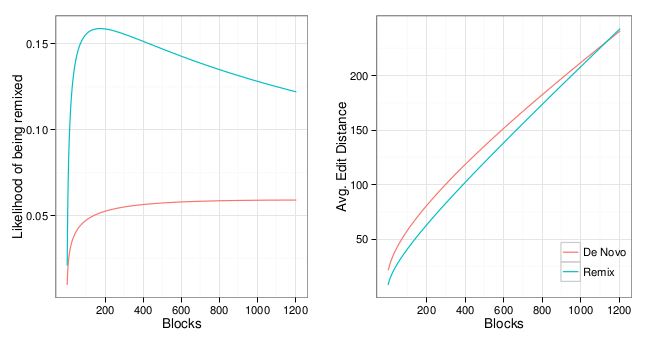
 But although I've spent quite a bit of time studying the Scratch
community in the last few years as it is grown to include millions of
participants and projects, I forgot about about Jay's photo shoot.
A couple months ago,
But although I've spent quite a bit of time studying the Scratch
community in the last few years as it is grown to include millions of
participants and projects, I forgot about about Jay's photo shoot.
A couple months ago,  That said, given the rather emotive nature of the pictures, I seem to
usually end up being
That said, given the rather emotive nature of the pictures, I seem to
usually end up being 
 There's quite many more entertaining examples
There's quite many more entertaining examples